왜 Tensowflow 인가
Tensorflow란?
지난 시간까지 신경망을 쌓으면서 모델을 학습, 즉 적절한 가중치와 바이어스를 구하는 방법을 이론적으로 알아보았습니다. 이번 게시글에선 이 방법들을 물리적인 코드로 구현해 보겠습니다. 하지만 코드로 구현한다고 하여 덧셈 뺄셈 연산자를 이용하여 밑바닥부터 구현한다는 의미는 아닙니다. 이미 시중에는 딥러닝을 초보자도 쉽게(?) 구현할 수 있도록 제작해 놓은 여러 라이브러리들이 있습니다. 이 중 우리는 가장 많은 사람들이 사용하는 Tensorflow를 사용할 것입니다.
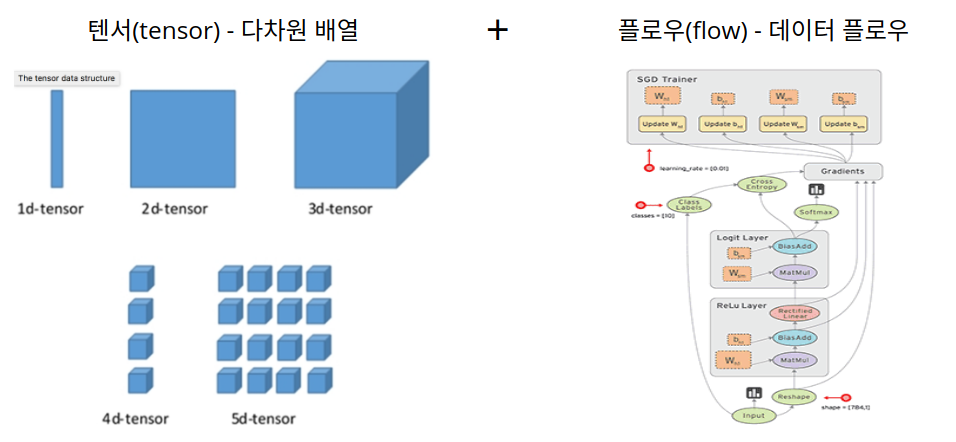
Tensorflow는 구글에서 만든 딥러닝을 쉽게 구현할 수 있도록 기능을 제공하는 라이브러리입니다. 위 그림과 같이 딥러닝을 할 사용되는 텐서 형태의 데이터들이 모델을 구성하는 연산들의 그래프를 따라 흐르면서 연산이 일어납니다. 데이터를 의미하는 텐서(tensor)와 데이터 플로우 그래프를 따라 연산이 수행되는 형태인 flow를 합쳐 텐서플로(tensorflow)라고 부릅니다.
Tensorflow 1? 2?
텐서플로는 현재 버전이 1과 2 두 가지가 있습니다. 두 버전의 차이는 다음과 같습니다.
- placeholder, session 사용X
- 필요한 기능은 함수로 구현, @tf.function 사용
- 훨씬 간단하다!
아직 텐서플로를 많이 사용해 보지 못해 모든 차이점을 말할 수는 없지만 요점은 2가 1보다 훨씬 간단하다는 뜻입니다. 텐서플로 1은 코드를 죽 짠 후, 맨 마지막 실행 단계에서는 session이라는 class를 통해 실행을 시키게 됩니다. 하지만 이렇다 보니 실행 단계에서 session이라는 블랙박스에 가까운 공간 안에서 작업이 수행되다 보니 개발자가 개입하기가 힘들었습니다. 하지만 텐서플로 2에서는 session을 없애고 keras라는 강력한 라이브러리를 텐서플로 라이브러에서 편입시키면서 더욱 쓰기 편한 라이브러리가 되었습니다. 따라서 처음 시작하는 분들은 텐서플로 2로 시작하는 것을 추천하지만, 예전 소스를 참고하기 위해선 텐서플로 1을 읽을 수 있는 방법도 알아야 하기에, 어느정도 비율을 조정해서 병행하는 것이 좋다고 생각합니다.
제가 수강하는 Udacity 강의는 텐서플로 1을 사용하였기 때문에 이 게시글은 텐서플로 1의 문법으로 작성하겠습니다.
Tensorflow 설치
Tensorflow는 일반적으로 Anaconda라는 가상 환경에서 설치 후 실행합니다. 하지만 Anaconda는 파이썬 3 이상의 버전을 지원하기 때문에 파이썬 2 이하의 버전이 필요하신 분, 또는 다른 파이썬 라이브러리와 같이 사용해야 하는 분은 아나콘다 설치를 권장하지 않습니다. 저는 OpenCV도 함께 설치되어 있기 때문에 아나콘다를 통해 설치하지 않았습니다. 제가 시도해 본 방법은 다음과 같습니다.
- pip install
- 공식 홈페이지 whl 설치
- Google Colab
1. pip install tensorflow
파이썬 패키지 라이브러리를 관리해주는 pip 명령어를 통해서 설치하는 방법입니다. 우분투로 치면 apt-get 명령어 정도의 포지션입니다. 일반적으로 파이썬을 설치했다면 설치되어 있겠지만, 혹시나 해서 설치 명령어를 남깁니다.
Python 2.X의 경우
$ sudo apt-get install python-pip
Python 3.X의 경우
$ sudo apt-get install python3-pip
pip가 설치되어 있다면 다음 명령어를 통해 설치합니다.
$ pip3 install tensorflow
이 명령어는 기본적으로 텐서플로 최신 버전을 설치합니다. 원하는 버전이 있다면 끝에 ==X.XX를 붙이거나 텐서플로 패키지 이름을 명시하여 설치합니다.
예시)
$ pip3 install tensorflow==1.15
$ pip3 install tensorflow-gpu==1.15
참고로 텐서플로 2는 cpu 패키지와 gpu 패키지가 통합되어 있다고 합니다.
2. 공식 홈페이지 msi 설치
위의 방법으로 설치는 할 수 있지만 개발 도구와 연동시키는 법을 몰라 저는 다음 방법으로 시도했습니다. 저는 Visual Studio Code로 코드를 작성하고 싶었기 때문에 whl 파일을 통해 설치했습니다. 공식 홈페이지 Tensorflow 설치 사이트에 가면 whl 파일을 받을 수 있는 링크가 있습니다. 저는 노트북에서 실행할 것이기 때문에 CPU만 지원하는 파일을 다운받았습니다.
$ wget https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.4.0-cp36-cp36m-manylinux2010_x86_64.whl
$ pip install tensorflow_cpu-2.4.0-cp36-cp36m-manylinux2010_x86_64.whl
이 방법을 통하여 설치하면 VSC에서 텐서플로를 사용할 수 있습니다.
3. Google Colab
마지막 방법은 Google Colab을 사용하는 것입니다. 이 방법은 텐서플로를 내 컴퓨터에 설치하는 방법이 아니라 오프라인에서는 사용할 수 없지만, 구글에서 이미 준비가 다 된 환경을 마련해 준다는 편리함이 있습니다. 게다가 서버 역시 구글에서 제공하기 때문에 컴퓨터 성능과 관계없이 코드를 실행할 수 있습니다. 성능이 좋지는 않지만 예제 정도를 실행하거나 시간이 많다 하시는 분들은 이 방법도 추천합니다. 하지만 코랩에 기본적으로 설치된 텐서플로는 최신 버전이기 때문에 텐서플로 1을 사용하고 싶다면 별도로 삭제, 설치할 필요가 있습니다. 코랩용 삭제, 설치 코드는 다음과 같습니다.
$ !pip3 uninstall tensorflow
$ !pip3 install tensorflow==1.15
페이지를 나갔다가 다시 접속하면 매번 설치해 줘야 한다는 번거로움이 있습니다. 하지만 어디서나 실행할 수 있다는 편리함 때문에 용서해 주겠습니다. 코드는 또 텐서플로 2에 맞춰서 짜면 해결되는 부분이기도 하고요.
Tensorflow 1 기본 함수들
텐서플로에서 사용하는 함수들에 대해서 알아보겠습니다.
tf.Session()
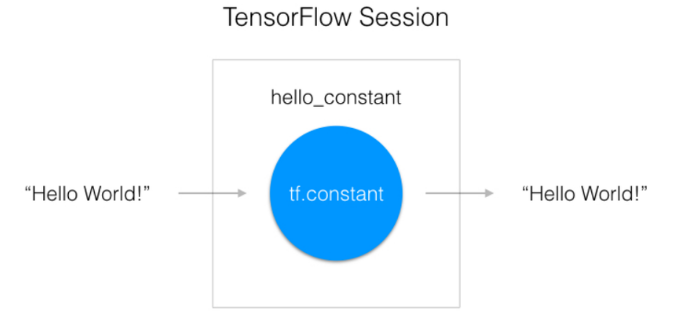
위에서 설명했듯이 작성한 코드를 실행하는 환경입니다. 먼저 코드를 짜고, Session에서 실행합니다. 하지만 텐서플로 2에서는 사용하지 않습니다.
tf.constant()
텐서 상수를 선언하는 함수입니다. 상수인 만큼 변하지 않는 텐서값입니다. 처음 정해준 값으로 끝까지 갑니다.
예시)
import tensorflow as tf
hello_constant = tf.constant('Hello world!')
with tf.Session() as sess:
hello = sess.run(hello_constant)
print(hello)
출력:
위의 코드와 같은 방식으로 tf.Session()을 사용합니다.
tf.사칙연산()
tf.add(), tf.multiply(), tf.subtract(), tf.divide() 함수가 있습니다. 덧셈, 곱셈, 뺄셈, 나눗셈 등 연산을 수행합니다.
예시)
import tensorflow as tf
a = tf.constant(11)
b = tf.constant(5)
ad = tf.add(a, b)
sub = tf.subtract(a, b)
mul = tf.multiply(a, b)
div = tf.divide(a, b)
with tf.Session() as sess:
r1 = sess.run(ad)
r2 = sess.run(sub)
r3 = sess.run(mul)
r4 = sess.run(div)
print('add: {}\nsubtract: {}\nmultiply: {}\ndivide: {}'.format(r1, r2, r3, r4))
출력:
add: 16
subtract: 6
multiply: 55
divide: 2.2
tf.placeholder()
딥러닝에서 학습할 데이터를 담는 데이터 타입입니다. 학습용 데이터를 담는 그릇이라고 생각하면 됩니다. tf.Session()과 마찬가지로 텐서플로 2에서는 사용되지 않습니다.
예시)
import tensorflow as tf
x = tf.placeholder(tf.int32, (None))
y = tf.placeholder(tf.int32, (None))
sum = tf.add(x, y)
with tf.Session() as sess:
result = sess.run(sum, feed_dict={x: 11, y: 5})
print('sum: {}'.format(result))
tf.Variable(), tf.global_variables_initializer()
상수와 초기화되지 않은 변수를 선언하는 방법을 보았으니 초기화와 동시에 변수를 선언하는 방법도 있습니다. 그것이 tf.Variable입니다. tf.global_variables_initializer()는 함수는 위의 코드에서 선언한 tf.Variable() 변수들을 세션에 적용해 주는 함수입니다. 예시는 다음과 같습니다.
예시)
import tensorflow as tf
x = tf.Variable(5, name='x')
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(x)
print('result: {}'.format(result))
출력:
tf.truncated_normal()
정규분포에서 랜덤 숫자를 뽑아내는 함수입니다. 주로 가중치를 초기화하는데 사용합니다. 가중치를 초기화할 때 정규분포를 사용하는 이유는 기울기 소실 때문입니다. 가중치를 랜덤으로 주면 Sigmoid 함수의 출력값이 0 또는 1에 아주 가까운, 즉 0 또는 1로 근사할 수 있는 출력값이 나오게 됩니다.
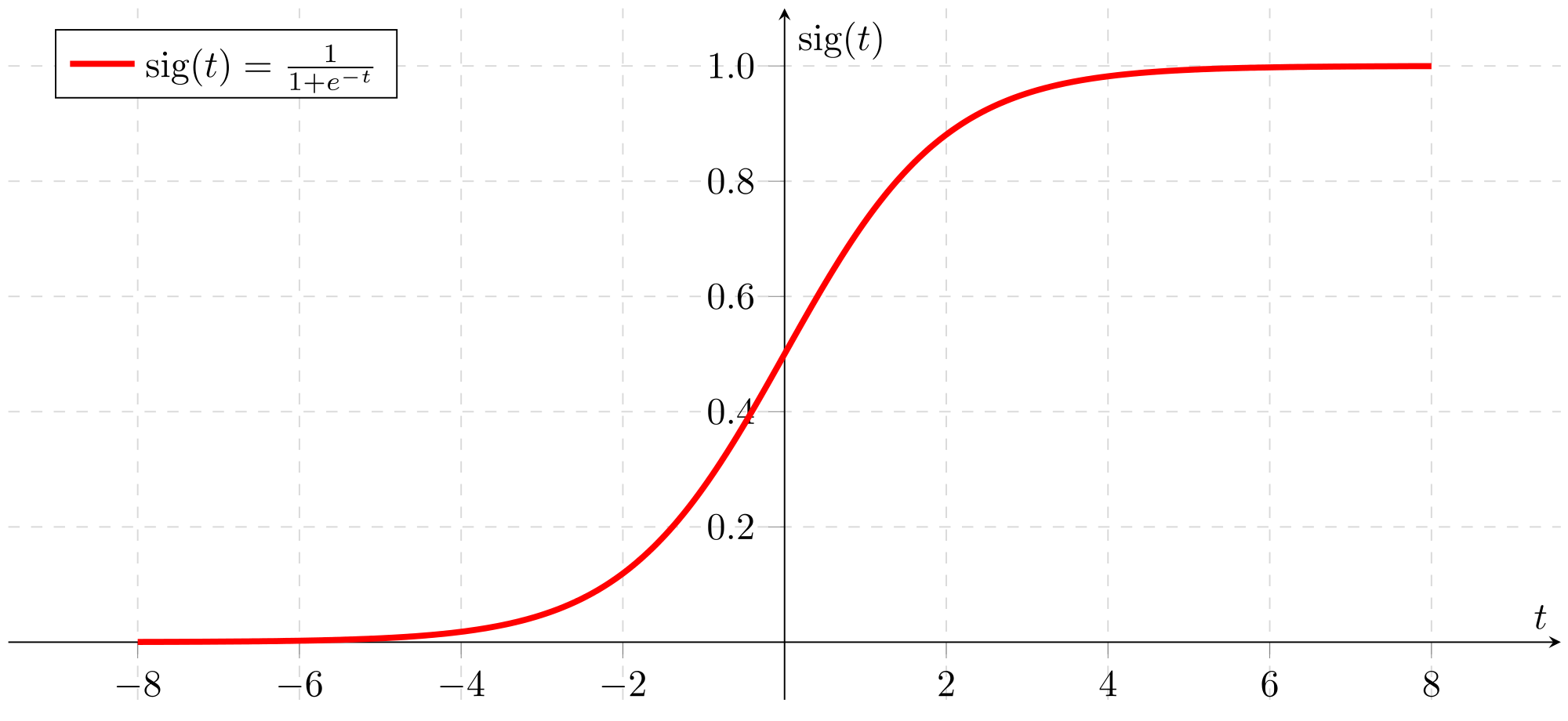
이때, 출력값이 0 또는 1로 가게 된다면 Sigmoid 함수의 미분값이 0으로 치닫게 되므로, 경사 하강법에서 활성화 함수인 Sigmoid 함수의 미분을 사용할 때 $\frac{\partial E}{\partial \sigma}\frac{\partial \sigma}{\partial z}\frac{\partial z}{\partial W}$ 중 $\frac{\partial \sigma}{\partial z}$의 값이 0이 되면서 가중치 수정값 역시 0이 됩니다.($z$는 선형 모델 결과값) 이렇게 오차함수의 기울기(Sigmoid 함수의 기울기)가 소실되는 현상을 기울기 소실(Gradient Vanishing Problem)이라고 합니다.
따라서 정규분포로부터 랜덤 가중치를 뽑게 된다면, $-\infty ~ +\infty$ 사이의 숫자보다는 평균 0 근처의 숫자가 주로 추출될 것입니다. 이러한 특징을 통해 가중치가 한쪽으로 압도되는 것을 막을 수 있습니다.
예시)
import tensorflow as tf
weights = tf.Variable(tf.truncated_normal(shape = (5, 5), mean = 0, stddev = 0.1))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(weights)
print('result:\n{}'.format(result))
출력:
result:
[[-0.01648159 -0.02329956 0.17793715 -0.06097916 -0.05726282]
[ 0.14564233 0.14883497 0.01122501 0.08220296 0.06075064]
[-0.0392657 -0.06555585 -0.00456797 0.00886977 -0.06788757]
[-0.10041036 0.12152421 0.09188548 0.05627985 -0.11565887]
[-0.04590392 0.03194086 0.09958582 -0.07237397 -0.06919689]]
대부분 평균 0 근처의 난수가 저장된 것을 볼 수 있습니다.
tf.zeros()
모든 텐서의 요소가 0인 텐서를 만드는 함수입니다. 바이어스를 초기화하는데 사용됩니다. 사용 방법은 weights 초기화 할때랑 비슷합니다.
예시)
import tensorflow as tf
bias = tf.Variable(tf.zeros(6))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(bias)
print('result:\n{}'.format(result))
출력:
result:
[0. 0. 0. 0. 0. 0.]
Tensorflow 학습 함수들
Softmax
소프트맥스 함수는 logits라는 입력을 0~1 사이의 확률값으로 바꾸는 함수입니다. 지난 게시글에 설명이 되어 있으니 자세한 설명은 생략하겠습니다. 사용 방법은 tf.nn.softmax(logits)입니다.
Cross-Entropy
크로스 엔트로피는 학습에서 사용하는 오차함수입니다. 이 부분 역시 이 게시글에 설명되어 있으니 생략하겠습니다. 텐서플로에서의 사용법은 다음과 같습니다.
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = one_hot_y)
loss_operation = tf.reduce_mean(cross_entropy)
Optimization - 최적화 단계
여기서 잠시 최적화 단계에 대해서 설명 드리겠습니다. 최적화는 모델 학습에서 가중치와 바이어스를 조절하는 단계를 의미합니다. 주로 경사 하강법을 사용합니다. 경사 하강법 역시 지난번에 다루었기에 간단하게 설명하겠습니다. 오차함수의 미분을 통해 오차가 작아질 때까지 가중치 수정을 반복하는 알고리즘입니다. 오차함수의 기울기가 음수면 가중치를 증가, 양수면 가중치를 감소시킵니다. 하지만 경사하강법의 두 가지 문제점인 시간이 오래 걸린다와 지역 최솟값에 빠질 수 있다를 해결하기 위해 확률적 경사 하강법과 모멘텀이라는 방법이 고안되었습니다.
Stochastic Gradient Descent(SGD, 확률적 경사 하강법)
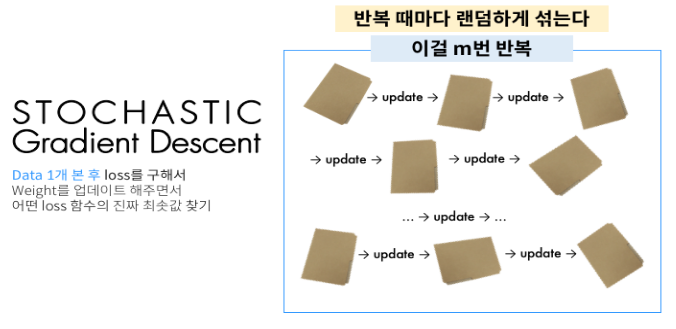
확률적 경사 하강법은 경사 하강법과는 다르게 랜덤으로 한개의 데이터만을 보고 계산하는 방법입니다. SGD의 장점은 적은 데이터로 학습할 수 있고 속도가 빠르다는 점입니다. 하지만 학습 중간 과정에서 결과의 진폭이 크고 불안정하며, 데이터를 하나씩 처리하기 때문에 GPU의 성능을 모두 활용하지 못한다는 단점을 가집니다. 따라서 이러한 단점을 보완하기 위해 Mini-Batch라는 방식을 사용합니다.

Mini Batch는 전체 학습데이터를 배치 사이즈로 나누어서 순차적으로 진행하는 방식입니다. Mini Batch SGD는 한개만 하던 그냥 SGD와는 다르게 데이터 일부분을 뽑아서 그 평균에 따라 가중치를 수정합니다. 이름에서도 알 수 있듯이 Mini Batch 방식과 SGD가 합쳐진 모습을 볼 수 있습니다. 병렬처리가 가능해지면서 GPU의 성능을 활용할 수도 있고 학습 중간 과정에서의 노이즈를 줄일 수 있습니다. 최근에는 거의 Mini Batch SGD를 사용하기 때문에 그냥 Mini Batch SGD를 SGD라고 부르기도 합니다.
Momentum(모멘텀)
모멘텀은 지역 최솟값에 빠지지 않도록 고안된 방법입니다. 원래 경사 하강법에서는 오차함수를 미분한 값만큼만 가중치를 조정했지만, 모멘텀을 적용하면 이전 단계에서 오차함수의 미분값의 일부를 이번 단계에서도 적용하여 진짜 최솟값인지 아닌지를 한번 보는 원리로 표현할 수 있습니다. 수식으로 나타내면 다음과 같습니다.
$\large{
v \leftarrow \alpha v-\eta \frac{\partial E}{\partial W}
}$
$\large{
W \leftarrow W+v
}$
여기서 $\alpha$로 이전 단계의 오차함수 미분값의 반영 비율을 조정합니다. 쉽게 설명하면 모멘텀, 즉 관성을 사용하여 원래 검사하려던 것보다 좀 더 멀리 뻗어보는 방법입니다.
Epoch
epoch는 전체 데이터 셋에 대해서 한번 학습을 완료한 상태를 의미합니다. 보통 Hyperparameter로 지정해 주게 되는데, Epoch은 배치를 사용하든 하지 않든 데이터의 전체 값을 모두 한번 본 상태여야 Epoch = 1인 상태라고 볼 수 있습니다. 결과적으로 전체 데이터 셋 학습 횟수로서 사용합니다. 예를 들어 EPOCH = 10이라고 지정해 줬다면 전체 데이터를 10번 학습하였다는 의미입니다.
마무리
Tensorflow에 대해서 알아보았지만 아직 많이 부족한 느낌입니다. 다음 게시글은 Deep Nerual Network를 정리할 예정입니다.
질문
- 그럼 모멘텀으로 못빠져나올만큼 깊은 지역 최솟값일땐 어떻게 하나요?
참고 사이트
Udacity Self-driving car nanodegree - Tensorflow(링크 공유 불가능)
Tensorflow 공식 홈페이지 - TensorFlow 설치
Broccoli’s House - #5-(2) 학습 관련 기술 : 초기 가중치 설정
Refstop
Deep Learning 및 SLAM을 공부하고 있습니다.

Comments