이산 모델에서 연속 모델로
저번 게시글에선 로지스틱 회귀의 이산 모델에 대해서 정리했습니다. 하지만 경사 하강법을 사용하기 위해서는 연속 모델을 사용해야 합니다. 이산 모델과 비교하여 연속 모델에서 추가된 과정은 다음과 같습니다.
- Sigmoid 함수 (확률함수)
- Maximum Likelihood Estimation (최대우도법)
- Cross-Entropy
- Gradient Descent (경사 하강법)
경사 하강법을 사용하기 위해서는 Cross-Entropy가 연속이어야 하고, Cross-Entropy에서 사용되는 최대우도법을 위해서는 확률 개념이 도입되어야 합니다. 이에 따라 선형 모델에 대한 확률을 나타낸 것이 바로 Sigmoid 함수입니다.
1. Sigmoid 함수
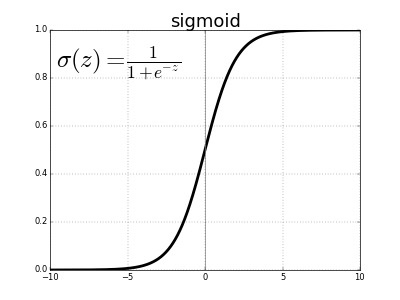
저번 게시글에서도 언급했던 시그모이드 함수입니다. 활성화 함수로 사용된다는 점에서 Step Function과 같은 포지션의 함수입니다. 하지만 Step Function과는 다르게 $x=0$을 기준으로 0과 1로 딱딱 맞게 나눠지지는 않습니다. 하지만 $x$의 절댓값이 약 5인 지점까지는 시그모이드 함수의 출력이 0 또는 1이 되지 않습니다. 이러한 점에 주목해 시그모이드 함수를 확률함수이자 활성화 함수로 사용합니다. 이 함수는 로지스틱 회귀에 활성화 함수로서 사용하기 때문에 로지스틱 함수라고도 불립니다.
2. Maximum Likelihood Estimation (최대우도법)
$\large{
P(x|\theta)=\prod_{k=1}^{n}P(x_k|\theta)\;\;\;\;\;\;\;P(x|\theta):\;예측이\;맞을\;확률
}$
그 다음 과정은 시그모이드 함수에서 구한 확률들에 최대우도법을 적용하여 가장 좋은 모델, 즉 가장 확률이 높은 모델을 선정합니다. 최대우도법은 각 데이터 샘플에서 예측이 실제와 같을 확률을 계산하여 모두 곱한 것입니다. 계산된 확률을 더해주지 않고 곱해주는 것은 모든 데이터들의 추출이 독립적으로 동시에 일어나는 사건이기 때문입니다. 따라서 최대우도법 계산 결과값이 가장 높은 것을 가장 정확한 예측으로 봅니다.
$\large{
ln(P(x|\theta))=\sum_{k=1}^{n}ln(P(x_k|\theta))
}$
하지만 이 경우 하나의 확률만 바뀌어도 결과값이 심하게 바뀌므로, 곱셈을 덧셈의 형태로 표현해 줄 수 있는 로그함수를 취합니다. 덧셈으로 바꾸면 값 하나가 바뀌어도 결과값에 큰 영향이 가지 않습니다. 이 결과는 Cross-Entropy 오차함수를 만드는데 사용됩니다.
3. Cross-Entropy 오차함수
Cross-Entropy는 오차함수로 출력값이 작을수록 모델이 정확하다는 의미를 나타냅니다. 지난 과정에서 log likelihood 함수에 1보다 작은 값인 확률을 대입하기 때문에 결과가 항상 음수입니다. 따라서 비교의 용이를 위해 (-)부호를 취해 양수로 만들어 줍니다.
$\large{
MLE=\sum_{k=1}^{n}ln(p_i)\rightarrow-\sum_{k=1}^{n}ln(p_i)
}$
그 다음 이진적으로, 예를 들어 선물이 있다/없다, 샘플이 제대로 분류 되었다/되지 않았다를 판단할 때는 한쪽의 확률을 $p_i$, 다른 쪽의 확률을 $1-p_i$로 둡니다. 그리고 확률이 $p_i$일 때를 $y_i$=1, $1-p_i$일때를 $y_i$=0으로 두면 다음과 같은 식을 세울 수 있습니다.
$\large{
Cross-Entropy = -\sum_{k=1}^{n}\left\{\begin{matrix}
ln(p_i)\;\;\;\;\;\;if\;y_i=1\\
ln(1-p_i)\;\;\;\;if\;y_i=0
\end{matrix}\right.
}$
이때 $y_i$는 실제값으로 볼 수 있는데, $p(x=1)$, $p(x=0)$의 확률로 볼 수 있습니다. 이처럼 확률이 0 또는 1만으로 결과가 나오는 확률변수를 베르누이 확률변수라고 합니다. 위의 공식을 한줄로 표현하면 다음과 같은 식으로 나타낼 수 있습니다.
$\large{
\begin{align*}
Cross-Entropy(y_i, p_i) &= -\sum_{k=1}^{n}\left\{\begin{matrix}
ln(p_i)\;\;\;\;\;\;if\;y_i=1\\
ln(1-p_i)\;\;\;\;if\;y_i=0
\end{matrix}\right. \\
&=-\sum_{k=1}^{n}y_iln(p_i)+(1-y_i)ln(1-p_i)
\end{align*}
}$
이 공식에서 Cross-Entropy의 이름이 왜 교차 엔트로피인지를 볼 수 있습니다. $y_i$와 $p_i$ 두 확률이 교차(Cross)하는 계산에 의해 Entropy, 즉 정보량이 정해진다고 하여 Cross-Entropy인 것입니다. 즉 두 확률을 기반으로 구한 정보량이 Cross-Entropy인 것입니다. 결과값을 관찰하면 값이 작을수록, 즉 관계성이 옅을수록 낮은 값이 나옵니다. 다음의 예시가 이해를 도와줄 것입니다.
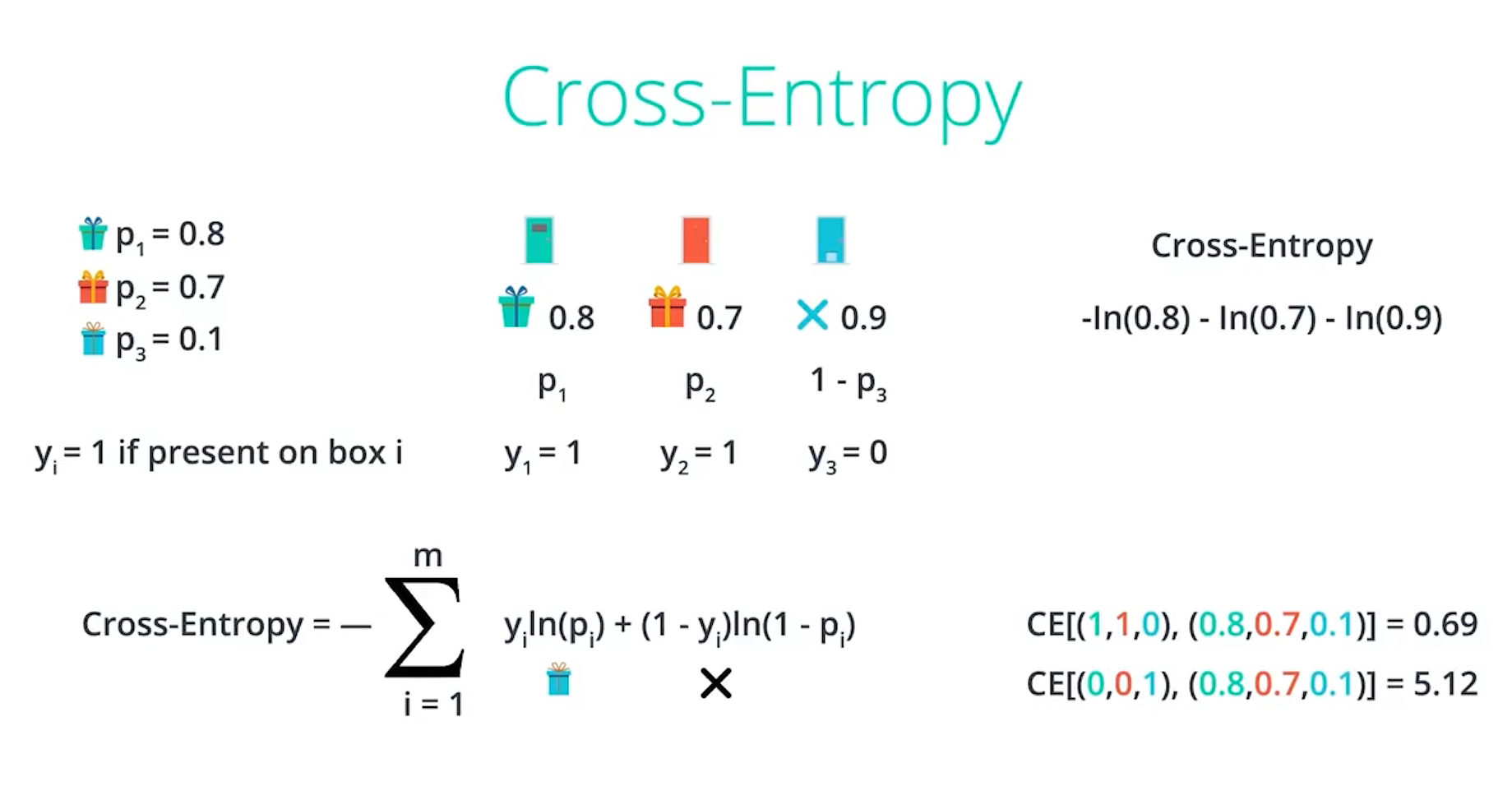
위의 예시는 3개의 문 뒤에 선물이 있을 확률을 나타낸 것입니다. n번째 문 뒤에 선물이 있을 확률은 각각 $p_n$입니다. 그리고 실제값 $y_i$는 선물이 있을 때 1, 없을 때 0을 의미합니다. 이때 일어날 확률이 가장 높은 값, 즉 예측값은 (0.8 0.7 0.9)이고 이때의 실제값은 (1 1 0)입니다. 따라서 이 확률과 실제값을 Cross-Entropy 오차함수에 대입하면 위의 그림에서 볼 수 있듯 0.69가 나옵니다. 반대로 가장 일어날 확률이 낮은 값, 즉 예측값에서 가장 먼 값을 Cross-Entropy 오차함수에 대입하면 5.12가 나옵니다. 예측값에서 작은 값을 출력되고, 예측값에서 먼 값일수록 큰 값을 출력하는 특징을 이용하여 Cross-Entropy를 오차함수로 사용합니다.
4. Gradient Descent
오차가 큰지 작은지를 구했다면 구한 오차를 기반으로 가중치와 바이어스를 보정합니다. 여기서 경사 하강법을 사용하는데, 이는 적절한 가중치와 바이어스를 찾는 방법입니다. 높은 산에서 경사를 따라 내려오듯이 오차의 미분값을 따라 가중치를 조정합니다. 이산 모델에서의 퍼셉트론 알고리즘과 비슷한 포지션에 있습니다. 다음 이미지는 평균 제곱 오차(이하 MSE)의 경사하강법을 나타낸 그림입니다. 가로축은 가중치 $W$, 세로축은 오차 $Error$입니다.
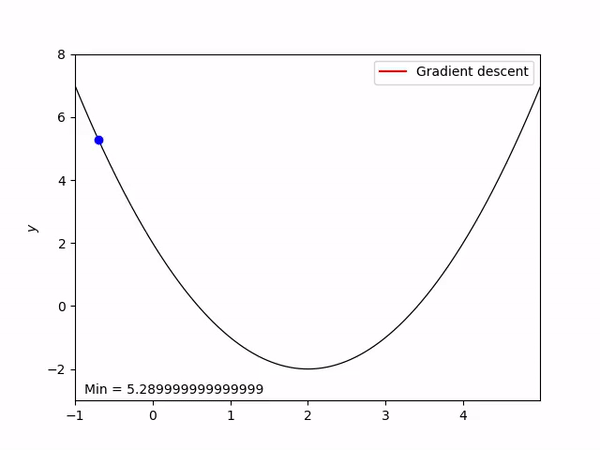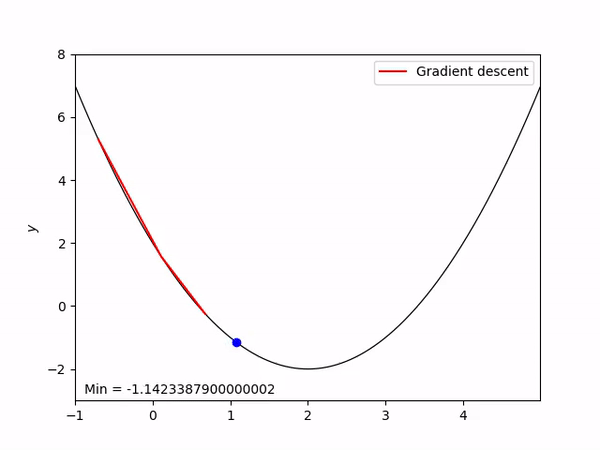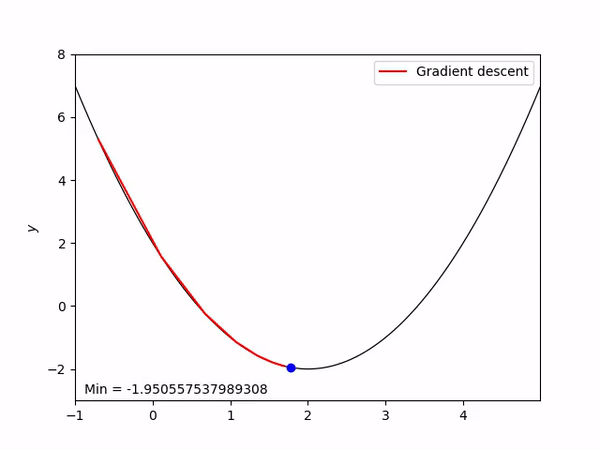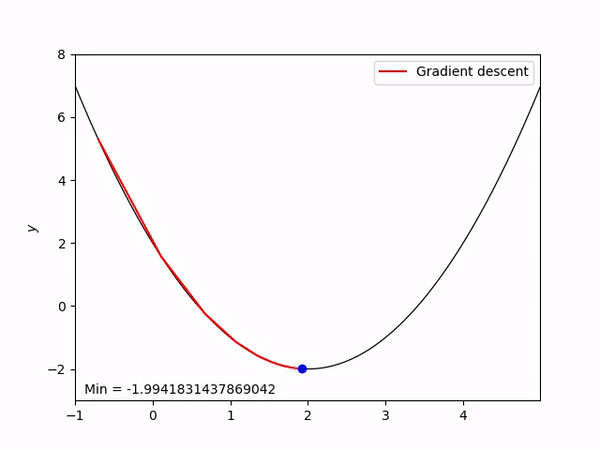
$\large{
E(W)=\frac{1}{2m}\sum_{k=1}^{m}(y_i-\sigma(Wx+b))^2
}$
MSE 함수는 오차함수로서 가중치와 오차의 관계를 2차 방정식으로 표현할 수 있습니다. 따라서 그림과 같은 형태의 그래프가 나오게 됩니다. 적절한 가중치를 찾기 위해서는 이 오차가 가중치에 끼치는 영향을 찾아 가중치에 더하거나 빼서 가중치를 보정해 줍니다. 그 과정은 다음과 같습니다.
$\large{
\hat{y}=\sigma(Wx+b)
}$
$\large{
\hat{y}=\sigma(w_1x_1+w_2x_2+\cdots+w_nx_n+b)
}$
선형 모델을 활성화 함수에 넣은 모습입니다. 출력값은 확률입니다.
$\large{
\triangledown E=(\frac{\partial E}{\partial w_1},\frac{\partial E}{\partial w_2},\cdots,\frac{\partial E}{\partial w_n})
}$
이때 오차함수는 MSE, Cross-Entropy 등을 사용합니다.
$\large{
\alpha=0.1\;\;(학습률)
}$
오차함수의 미분값을 얼마나 반영할 것인지 정합니다. 학습률이 너무 작으면 오차 최솟값까지 가는데 시간이 너무 오래 걸릴 수 있고, 학습률이 너무 크면 가중치가 오차 최솟값이 되는 지점을 넘어가버려 오차 최솟값에 수렴하지 못할 수 있습니다.
$\large{
w_i' \leftarrow w_i - \alpha\frac{\partial E}{\partial w_i}
}$
$\large{
b_i' \leftarrow b_i-\alpha\frac{\partial E}{\partial b}
}$
가중치와 바이어스에 오차함수의 미분에 비례한 값을 조정해 줍니다. 미분값이 작아질수록 가중치 변화가 작아지고, 0이 되면 최적 가중치가 됩니다. 모든 샘플에 대해 이 과정을 수행하기 때문에 이 새로운 가중치로 다시 경사 하강법을 수행합니다.
$\large{
\hat{y}=\sigma(W'x+b')
}$
Cross-Entropy의 W-Error 그래프
사실 경사하강법에서 가장 문제가 되는 부분은 오차함수의 미분을 구하는 부분입니다. 그 이외에는 간단하기에 Cross-Entropy 오차함수의 미분을 구하는 방법을 알아보겠습니다. 먼저 시그모이드 함수의 미분을 구합니다.
$\large{
z=Wx+b
}$
$\large{
\hat{y}=\sigma(z)\;(Sigmoid)
}$
$\large{
\frac{\partial \sigma}{\partial z}=\sigma(z)(1-\sigma(z))
}$
시그모이드 함수의 미분은 간단하게 $\sigma(z)(1-\sigma(z))$로 표현할 수 있습니다. 다시 Cross-Entropy 오차함수를 참고하면 다음과 같습니다.
$\large{
E(W)=-\sum_{k=1}^{n}y_iln(\sigma(z))+(1-y_i)ln(1-\sigma(z))
}$
미분하기 두려워지게 생겼지만 괜찮습니다. 연쇄법칙을 적용하여 $\frac{\partial E}{\partial W}$를 풀어줍시다.
$\large{
\begin{align*}
\frac{\partial E}{\partial W}&=\frac{\partial E}{\partial \sigma}\frac{\partial \sigma}{\partial z}\frac{\partial z}{\partial W}\;\;\;(연쇄법칙) \\
&=(\frac{1-y_i}{1-\sigma}-\frac{y_i}{\sigma})(\sigma(1-\sigma))X \\
&=(\sigma(z)-y_i)X \\
&=(\hat{y}-y_i)X
\end{align*}
}$
미분하기 어렵게 생겼던 것 치고는 간단한 형태의 미분값이 나왔습니다. 이 값을 다음 식에 대입하여 새로운 가중치와 바이어스를 찾습니다.
$\large{
w_i'\leftarrow w_i-\alpha \frac{\partial E}{\partial W}
}$
$\large{
w_i'\leftarrow w_i+\alpha (y_i-\hat{y})x_i
}$
$\large{
b_i'\leftarrow b_i-\alpha \frac{\partial E}{\partial b}
}$
$\large{
b_i'\leftarrow b_i+\alpha (y_i-\hat{y})
}$
생각보다 간결한 결과가 나왔습니다. 경사하강법은 이 과정을 모든 샘플에 대해 반복하여 가중치와 바이어스를 조정합니다. MSE의 그래프는 Cross-Entropy의 W-Error 그래프에 비해 직관적이기에 이해하기 쉽지만, 실제 Cross-Entropy 오차함수는 무시무시하게 생긴 경우가 많습니다. 실제 Cross-Entropy의 함수는 아니지만, 다음 그림처럼 아주 복잡한 함수를 예시로 들어 봅시다.
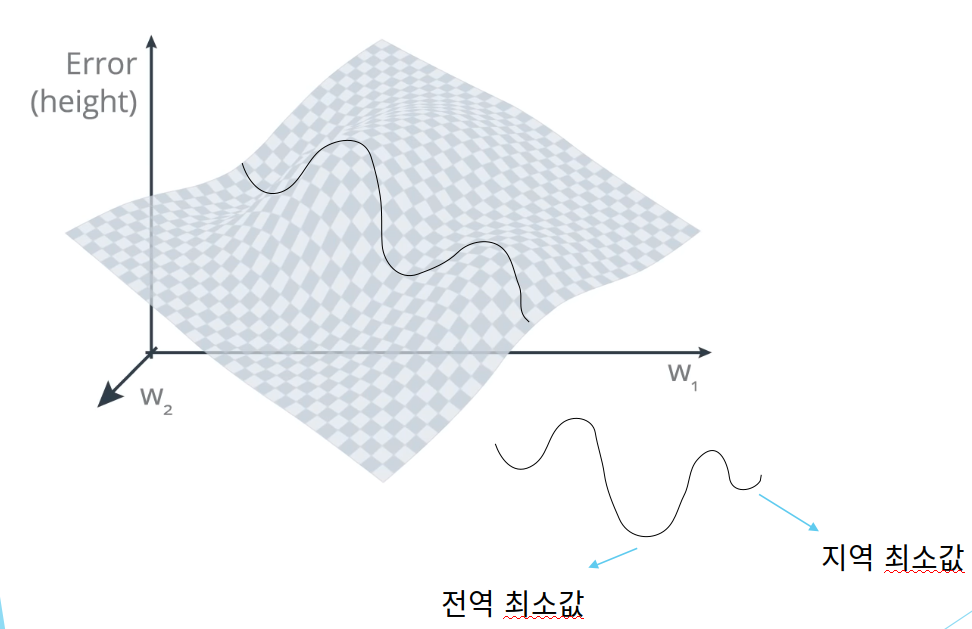
경사 하강법을 사용하는 데는 두 가지 문제가 있습니다.
첫번째는 그림에서 볼 수 있는 전역 최소값과 지역 최소값이 존재한다는 점입니다. 우리의 목표는 당연히 오차가 가장 낮아지는 전역 최솟값을 찾는 것입니다. 하지만 경사 하강법에는 지역 최소값에 대한 면역요소가 없기에, 지역 최소값에 속아넘어갈 수 있습니다. 이 문제를 해결하기 위해 고안된 것이 모멘텀(Momentum)이란 방법입니다. 기존에 업데이트했던 미분값의 일정 비율을 남겨서 현재의 미분값에 더하여 가중치를 업데이트 하는 방식입니다.
두번째 문제는 모든 데이터를 계산하기에 수고가 많이 든다는 점입니다. 퍼셉트론 알고리즘과 다르게 맞는 샘플도, 틀린 샘플도 모두 검사하기에 계산량이 매우 많습니다. 이 문제를 해결하는 방법은 무작위로 샘플을 뽑아서 가중치 업데이트를 수행하는 확률적 경사 하강법(Stochastic Gradient Descent, SGD)입니다. 완전히 정확한 결과를 얻는 것은 아니지만, 무작위 추출된 샘플이란 점에서 평균에 가까운 결과를 얻을 수 있고, 무엇보다 시간을 많이 단축시킬 수 있어 사용하는 방법입니다.
Perceptron Algorithm VS Gradient Descent
퍼셉트론 알고리즘과 경사 하강법의 차이는 바로 샘플의 검사 범위입니다. 퍼셉트론 알고리즘은 잘못 분류된 샘플만 검사하고, 경사 하강법은 모든 샘플을 검사합니다. 따라서 모델은 경사 하강법이 더 정확하게 만들지만 수행하는데 걸리는 시간은 퍼셉트론 알고리즘이 더 짧습니다. 공학은 역시 Trade-off입니다.
Softmax와 One-Hot Encoding
$\large{
Softmax(z)=\frac{z_i}{\sum_{k=1}^{n}z_i}\;\;\;\rightarrow\;\;\;\frac{e^{z_i}}{\sum_{k=1}^{n}e^{z_i}}
}$
소프트맥스는 시그모이드, step function과 같은 활성화 함수입니다. 3개 이상의 범주에 대한 확률을 나타낼때 사용합니다. 선형 모델의 각 결과값$(z_i)$을 모든 결과값의 합으로 나누어 표현합니다. 이는 결과값인 확률들의 총합을 1로 만들기 위함입니다. 하지만 이때 선형 모델의 결과값이 음수인 원소가 있을 때, 분모가 0이거나 0 이하로 내려가는 문제가 발생합니다. 소프트맥스는 활성화 함수로서 출력이 확률, 즉 양수로 나와야 하기 때문에 이 문제를 해결하기 위해 exp 함수를 사용합니다. exp 함수를 사용하면 선형 모델의 결과값의 합이 음수로 나오거나 분모가 0이 되는 경우를 막을 수 있습니다. 다음 그림으로 예시를 들겠습니다.
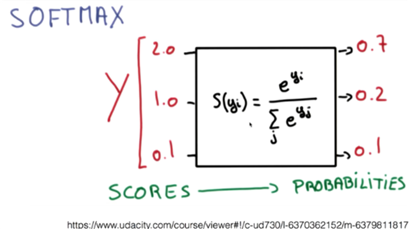
선형 모델의 결과가 (2.0 1.0 0.1)일 때, 결과값은 (0.7 0.2 0.1)이 나옵니다. 실제 결과값은 (0.6590011388859679, 0.2424329707047139, 0.09856589040931818)이지만, 소수점 둘째 자리에서 반올림한 값으로 생각합시다. 선형 모델의 결과가 높을수록 높은 확률이 출력되고, Softmax 함수의 출력값을 합하면 1이 되는 특징을 갖고 있습니다.
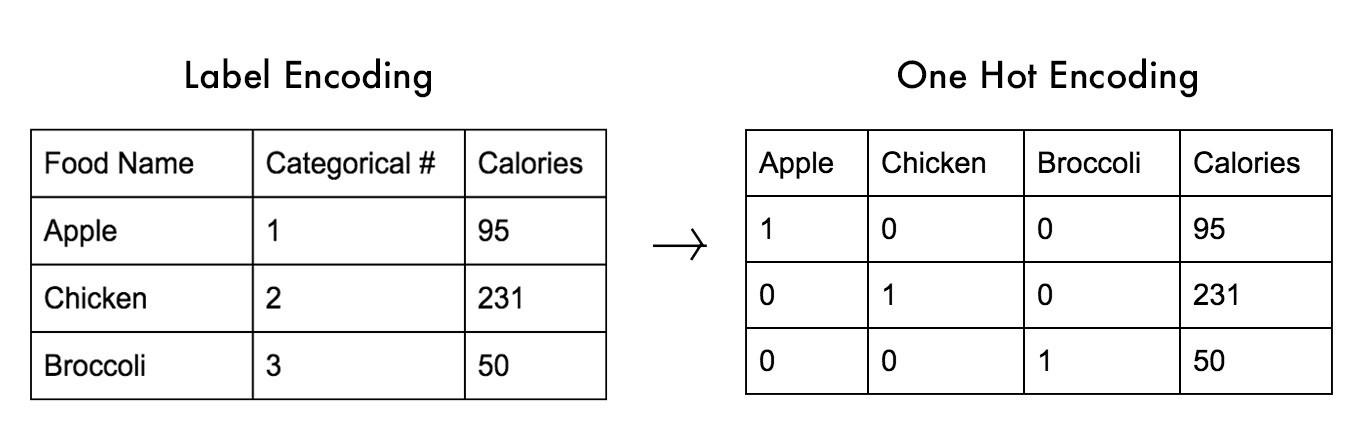
원 핫 인코딩은 정답만을 1로 만드는 데이터 전처리 방식입니다. 컴퓨터가 데이터를 학습하기 전에 데이터를 가공해주는 것입니다. 정답에 1을 부여하고 정답이 아닌 항에는 0을 부여합니다. 예를 들어 위의 표에서 [1, 0, 0] 벡터는 사과를 의미합니다. [0, 1, 0] 벡터는 치킨을 의미합니다. 이 방식으로 크로스 엔트로피에 들어갈 실제값 데이터를 만듭니다. 다음 그림을 통해 예시를 살펴보겠습니다.
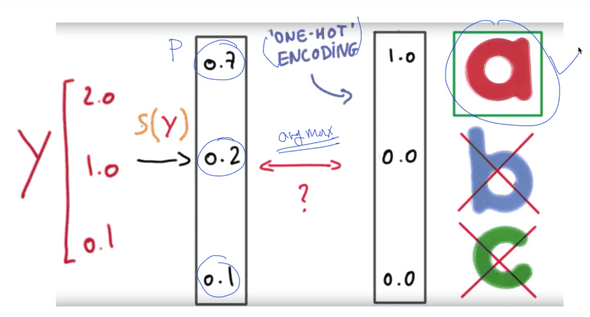
Softmax 결과값과 실제값 데이터를 전처리한 One-Hot Encoding 값을 비교합니다. 이 차이를 가지고 오차함수로 사용합니다. 이 경우, 그냥 |One-Hot Encoding 값 - Softmax 결과값|을 하여 오차를 구할 수도 있습니다. 이 방법을 사용하여 평균을 구한 것이 위에 잠깐 나왔던 MSE(평균 제곱 오차) 함수입니다. 하지만 여기서는 Cross-Entropy를 사용합니다.
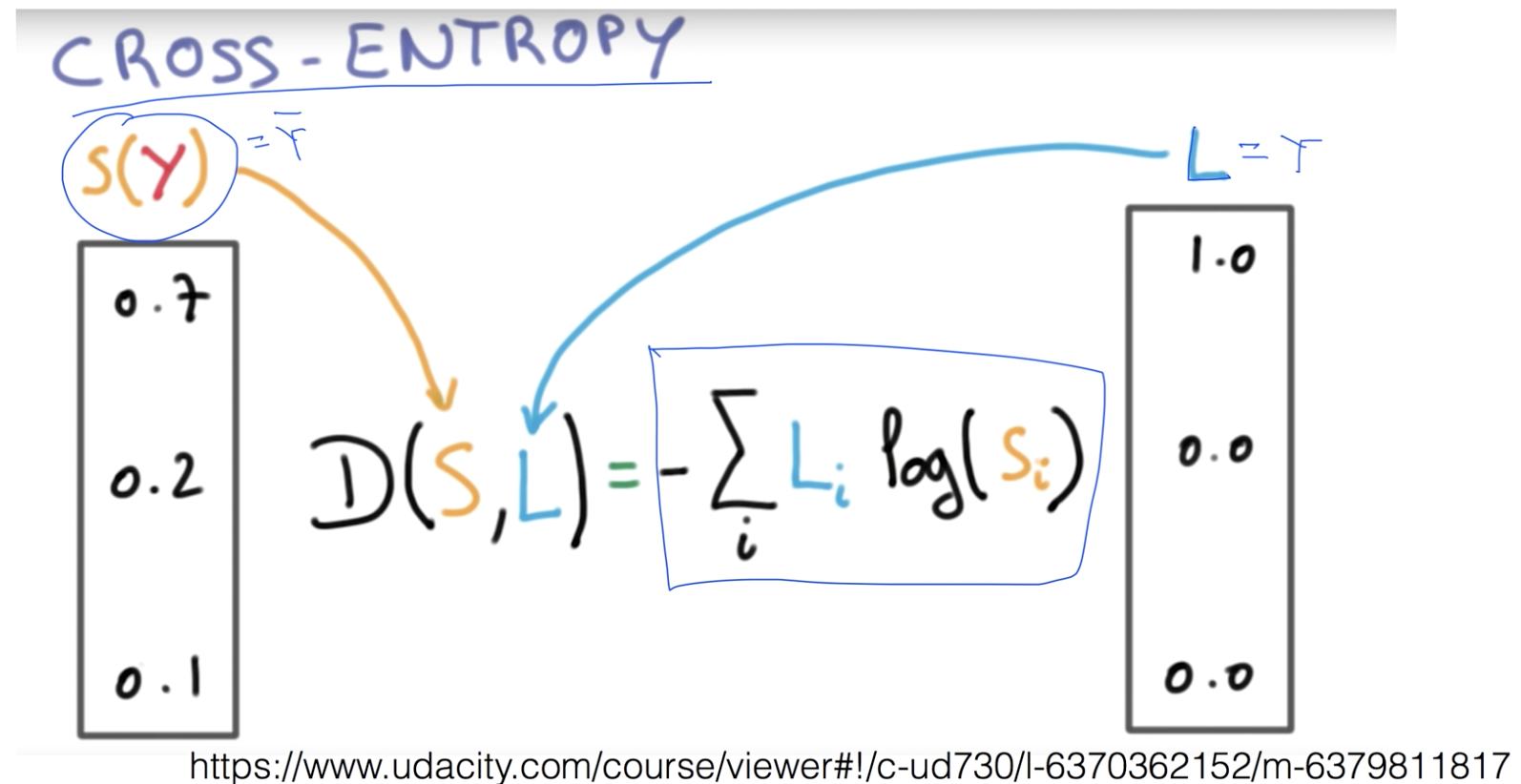
Softmax 함수의 결과값인 $S(y)$와 One-Hot Encoding의 결과인 라벨 $L$을 Cross-Entropy 오차함수에 대입하여 오차를 구합니다. 그러고 나면 위에서 설명했듯 Cross-Entropy는 두 확률간의 관계를 나타내는 방식으로 오차를 산출합니다.
마무리
다음 게시글은 NN의 비선형 모델에 대해 정리하겠습니다. 너무 길어 3편으로 나누어서 정리했네요. 한 강의에 이걸 다 넣을줄이야… 아무튼 다음 게시글에서 NN을 마무리하겠습니다.
질문
- 이산 모델에서 연속 모델로 변경하는 이유를 잘 모르겠습니다. 정리한 게 맞나요?
- 최대우도법에서 초기 확률을 부여하는 법?
- MSE보다 Cross-Entropy를 사용하는 이유?
참고 사이트
Udacity Self-driving car nanodegree - Neural Network(링크 공유 불가능)
ratsgo’s blog - 로지스틱 회귀
공돌이의 수학정리노트 - 최대우도법(MLE)
John 블로그 - 데이터 전처리 : 레이블 인코딩과 원핫 인코딩
Refstop
Deep Learning 및 SLAM을 공부하고 있습니다.

Comments